kafka(一) 概述
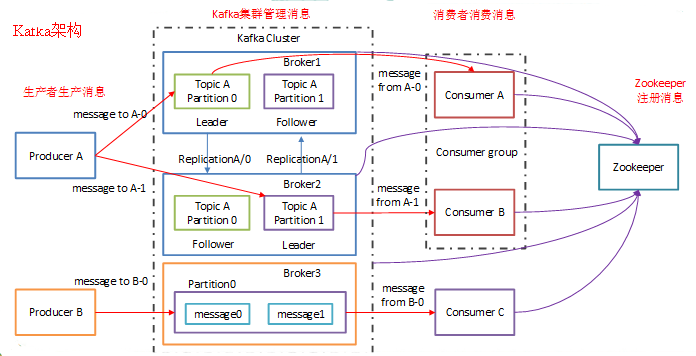
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以收集并处理用户在网站中的所有动作流数据以及物联网设备的采样信息。
基本组成部分
broker
集群的基本单位,一台kafka服务器即为一个broker.多个broker组成一个kafka集群,broker之间没有主从之分,地位都是平等的.
topic 主题
主题,每条消息发布到kafka的一个类别,用于区分消费.物理上不同的topic的消息分开存储,逻辑上只需指定topic主题即可消费与生产数据,无需关心数据具体在何处.
partition 分区
一个主题可以被分为多个partition,分布到多个broker.这里的partition可以视为一个queue队列.每条消息都会被分配一个自增id,各个partition的自增id又独立计算,所以,kafka只能保证一个partition中的记录能顺序读取,但无法保证一个topic下多个partition的记录能顺序读取.
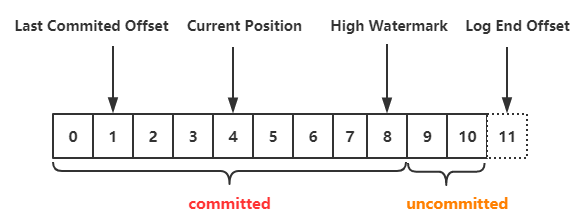
offect 游标
记录消息在partition中的位置.生产者的写数据,消费者的消费数据与副本之间的同步数据都涉及到offect.
- Last Committed Offect: 消费成功的最末尾数据位置.
- Current Position: 当前消费数据的位置.与last committed offect 之间的数据为拉取成功,但未提交的记录.由于消费者可能一次性拉取多条记录.
- Log End Offset: 即将插入的记录位置,对于生产者而言就是下一条插入消息的offset.对于日志而言,记录底层日志的下一条消息的offect.
- High Watermark: 已经成功备份到其他副本的最新一条消息的offect.
replica 副本
主题(topic)的分区(partition)存有多个副本,其中一个为leader,其他为follower.leader处理partition所有的读写请求,follower只定期同步leader的数据.
当leader失效,follower将选举出一个新的leader.
当follower失效或同步太慢,leader会将其剔除in sync replicas 列表,重新创建一个follower.
message 消息
通信的基本单位.生产者生产与消费者消费的最小单位.
// 消息保存在磁盘中 持久化时间, 数据保留时间 默认168小时
log.retention.houses=168
producer 消息生产者
将消息发布到指定的topic,可以指定发往的分区.
consumer 消息消费者
向指定的topic获取消息,通过指定topic的分区索引及其对应分区上的消息偏移量来获取消息.
consumer group 消息消费者组
每个consumer属于一个特定的consumer group.
consumer group中的consumer会进行负载均衡,均匀绑定partition来消费消息,一个partition中的消息只会被相同的consumer group中的某一个consumer消费.而每个consumer group相互独立.这也是kafka用于实现topic消息的广播(发所有的consumer)与单播(发单个consumer)的手段.
**zookeeper **
存放kafka集群相关元数据的组件:
topic的状态信息,分区个数,组成与分布情况.
broker的状态信息.
消费者的消费信息.
kafka的特性
高吞吐,低延迟
kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒.得益于其存储分布式架构与写入的Memory Mapped Files(MMF)与读取时候的Direct Memory Access(DMA)处理.
可扩展性
集群支持热扩展,通过增加broker的数量来达到性能上的提升.
持久性,可靠性
消息被持久化到本地磁盘默认持久化七天的数据,并且支持数据备份防止数据丢失,即每个partition都有备份,备份的个数由创建topic的时候定义.
容错性
允许集群中的节点失败.失败了的节点中的
leader partition会被其flower备份节点选举出一个新的leader来提供服务.
flower partition会被踢出ISR列表,并重新找一个broker建立一个flower partition备份.
高并发
支持数千个客户端同时读写.
应用场景
日志收集: 收集各种服务的log,通过kafka统一接口服务的方式开放给各种consumer,eg:hadoop,hbase,solr.
- 用户活动跟踪: 记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,订阅者通过订阅相关的topic来做实时监控或离线分析与挖掘.
- 运营指标: 记录运营监控数据,收集分布式应用的数据,分析生成报告或者警报.
消息系统: 解耦 生产者与消费者, 服务于服务之间的耦合.
流式处理: 用spark stream 与 stream来实时分析或计算.